

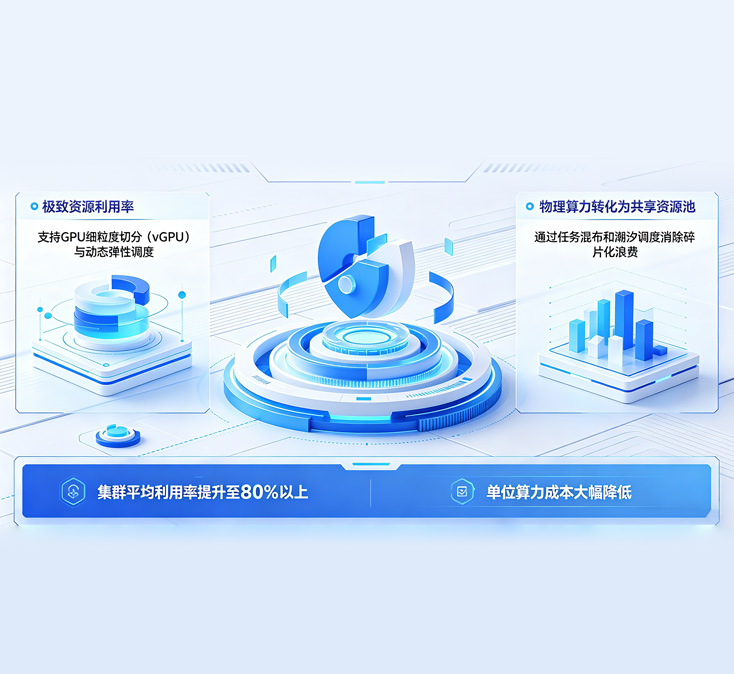
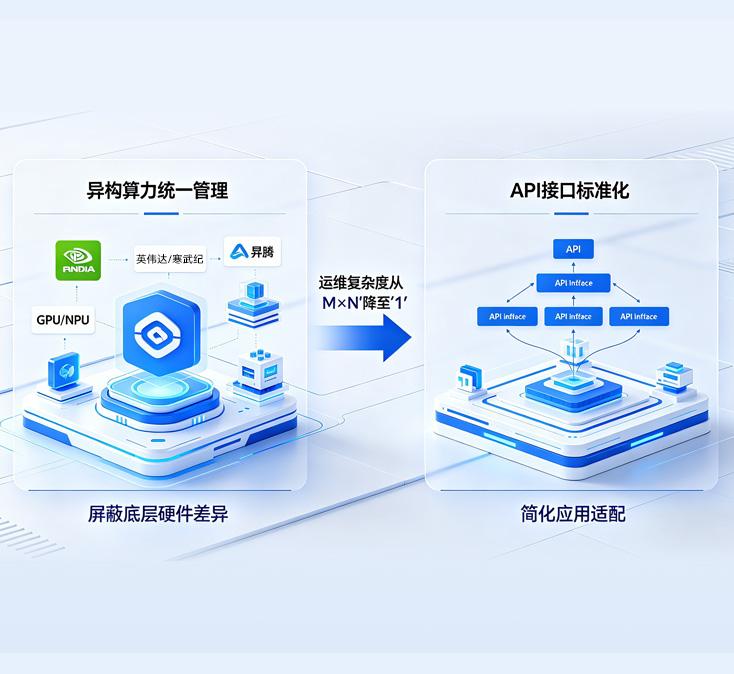
本方案打造一体化智算运营平台,实现 CPU/GPU 异构算力统一池化、智能调度与运维。平台支持算力虚拟化、任务调度、多租户、vGPU 切分与容器化部署,可将资源利用率提升至 80% 以上,大幅降低成本。平台具备可视化监控、自动告警与租户配额管理,支持计量计费与成本分摊,支撑商业化运营,赋能各行业 AI 训练推理,加速业务创新。


算力扩展瓶颈:传统以太网络无法满足千卡级AI训练对于网络延时和高带宽的苛刻要求;
运维复杂度高:100台服务器人工运维成本高、故障响应慢,缺少自动化监控、根因分析工具支撑;
能耗成本高:GPU集群功耗巨大,传统风冷PUE>1.4,运营成本居高不下;
交付周期长:项目要求2个月完成交付上线,企业传统自建算力中心很难满足交付周期要求。
运维管理:智算中心2栋楼整体管理难度大,效率低。

极致性能:A800集群+200G IB组网,通过低延迟和高带宽IB网络,GPU利用率30%+,同时具有灵活的可扩展性;
运维效率提升:集成DCOM+AIOps平台,实现故障预测、自动化巡检,故障定位速度提升50%+;
TCO优化:液冷散热降低30%+制冷能耗,满足PUE合规的同时,显著降低运营成本。
交付及时:采用模块化的交付标准流,两个月内完成项目交付上线,确保客户模型训练任务如期开展。
















